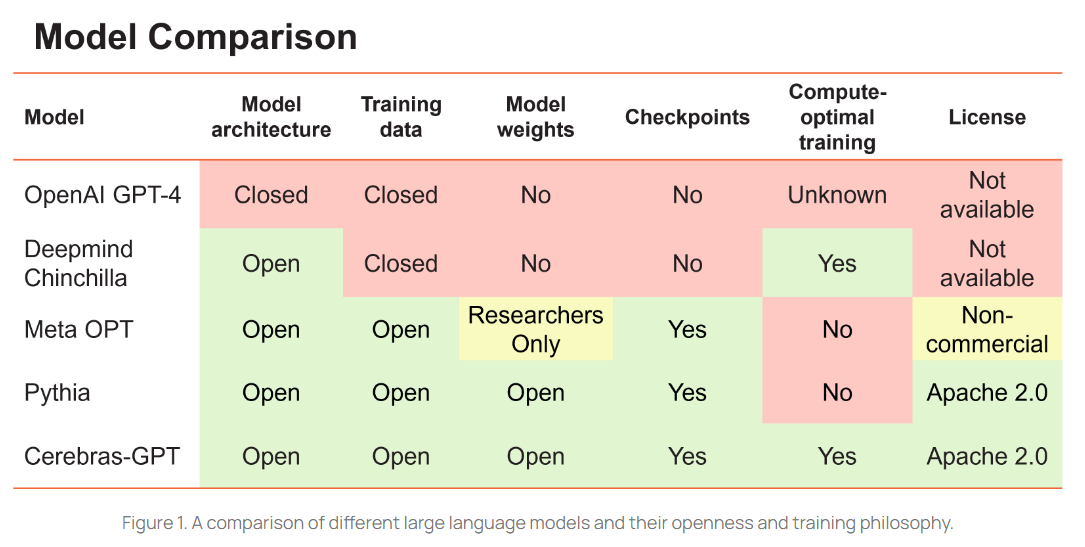
Cerebras-GPT es una familia de modelos de lenguaje grandes (LLM), abiertos y eficientes desarrollados por la empresa Cerebras Systems. Estos modelos de inteligencia artificial están diseñados específicamente para trabajar con grandes conjuntos de datos de lenguaje natural y son capaces de realizar tareas de procesamiento de lenguaje natural con una precisión notable. En este artículo, exploraremos las características de los modelos de lenguaje grandes, la eficiencia y el rendimiento de Cerebras-GPT, y las aplicaciones y el futuro de esta familia de modelos de lenguaje abiertos.
Los 7 nuevos Modelos liberados por Celebras-GPT
Celebras-GPT ha liberado a la comunidad open-source 7 modelos GPT que van desde los 111 millones de parámetros hasta los 13.000 millones. Entrenados en sus sistemas CS-2 demuestran, en comparación con el famoso Chat-GPT de OpenAI, que un modelo más pequeño pero bien entrenado puede producir igual o mejor resultado.
Los modelos listos para su uso pueden descargarse en las siguientes plataformas:
De momento tienen algunas limitaciones, por ejemplo el idioma: solamente han sido entrenados en inglés, pero estoy seguro que en breve nos deleitarán con nuevos avances.
Características de los Modelos de Lenguaje Grandes
Los modelos de lenguaje grandes son una clase de modelos de inteligencia artificial que se entrenan en grandes conjuntos de datos de lenguaje natural. Estos modelos son capaces de aprender patrones en el lenguaje natural que pueden ser utilizados para realizar tareas como la traducción automática, el análisis de sentimientos y la generación de texto. Los modelos de lenguaje grandes suelen tener cientos de millones o incluso miles de millones de parámetros, lo que les permite capturar patrones de lenguaje más complejos y realizar tareas de procesamiento de lenguaje natural con mayor precisión.
Eficiencia y Rendimiento de Cerebras-GPT
Cerebras-GPT se basa en una arquitectura de procesamiento en paralelo que utiliza una gran cantidad de núcleos de procesamiento para acelerar el entrenamiento del modelo. Esto permite que Cerebras-GPT pueda entrenar modelos de lenguaje grandes en tiempos mucho más cortos que los sistemas de procesamiento de lenguaje natural tradicionales. Además, Cerebras-GPT utiliza una técnica conocida como compresión de modelo para reducir el tamaño del modelo sin comprometer la precisión. Esto permite que Cerebras-GPT maneje modelos de lenguaje más grandes y complejos que otros sistemas de procesamiento de lenguaje natural.
Aplicaciones y Futuro de la Familia de Modelos de Lenguaje Abiertos
La familia de modelos de lenguaje abiertos de Cerebras-GPT tiene una amplia gama de aplicaciones potenciales en una variedad de campos. Por ejemplo, estos modelos podrían utilizarse para mejorar la precisión de los sistemas de chatbot y asistente virtual, lo que permitiría una interacción más natural entre los humanos y las máquinas. Además, los modelos de lenguaje abiertos podrían utilizarse para mejorar la traducción automática y la generación de texto, lo que permitiría a las empresas comunicarse con clientes de todo el mundo de manera más efectiva. En el futuro, es probable que veamos un aumento en el uso de modelos de lenguaje abiertos en una variedad de aplicaciones de inteligencia artificial.
En resumen, Cerebras-GPT es una familia de modelos de lenguaje grandes, abiertos y eficientes que están diseñados para ofrecer una precisión excepcional en el procesamiento de lenguaje natural. Estos modelos tienen el potencial de transformar una variedad de campos, desde el servicio al cliente hasta la traducción automática y la generación de texto. A medida que la tecnología continúa evolucionando, es probable que veamos un aumento en el uso de modelos de lenguaje abiertos en una amplia gama de aplicaciones de inteligencia artificial.


duspatal
duspatal
metoprolol tartrate
metoprolol tartrate